News
Passionate – Dedicated – Professional
latest news & insights
When the Token Bill Comes Due: What Uber and Microsoft Just Taught the Rest of Us About Renting Intelligence
In late May, Goldman Sachs put a number on something a lot of operators have been feeling in their gut for months. Agentic AI, the bank projects, could push token demand up by more than 24 times in the next few years. Read that again. Not 24 percent. Twenty-four times. If your [Read more...]
When Google Validates Your Architecture: Private AI Was Never the Alternative
At Google Cloud Next 2026 in Las Vegas this week, Google made a quiet but significant announcement: Gemini can now run on a single air-gapped server, fully disconnected from the internet — and from Google itself.
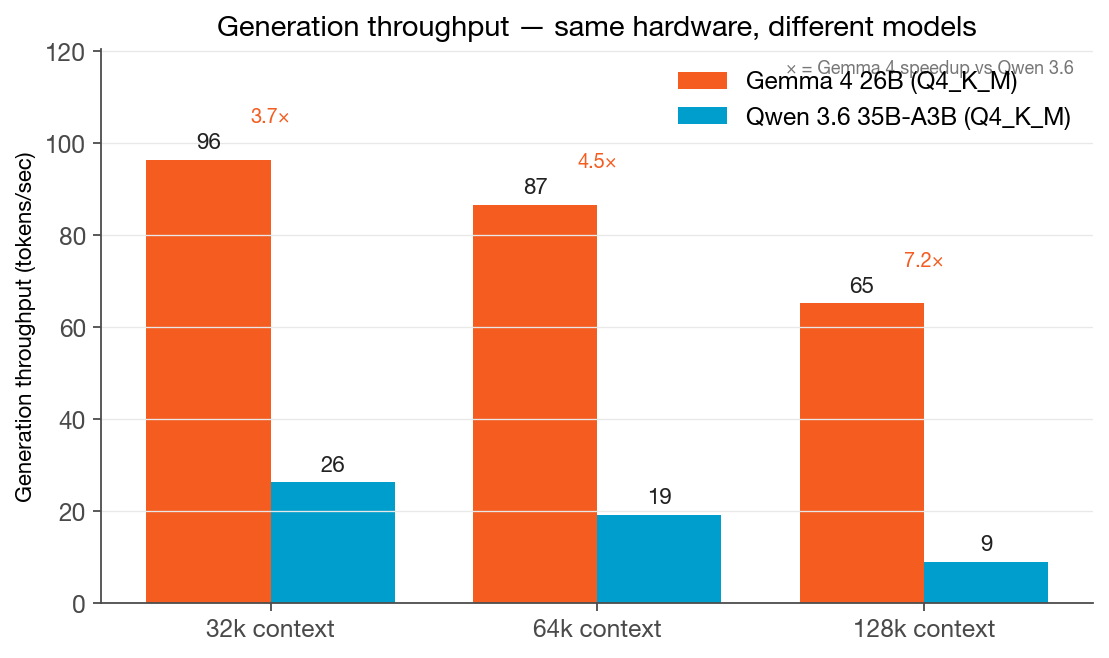
The Model That Barely Slows Down: Gemma 4 26B vs Qwen 3.6 35B at Long Context
We ran Gemma 4 26B and Qwen 3.6 35B-A3B head-to-head on the same server, same quantization, same protocol. Gemma 4 is 3.7× faster at 32k context — and 7.2× faster at 128k. The gap widens with context, and the reason reveals something important about model selection for long-context workloads.
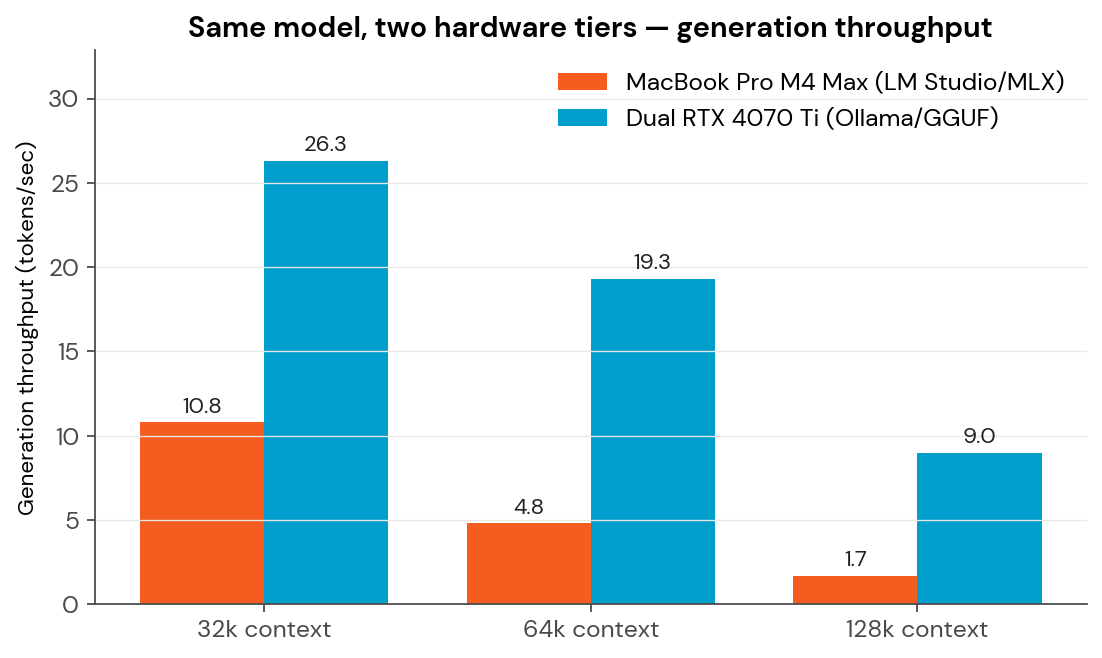
Same AI Model, Two Hardware Tiers — And Why Context Length Is the Hidden Variable
We put Qwen 3.6 35B-A3B on a developer laptop and a dual-GPU server. The speed gap grows from 2.4× to 5.3× as context grows — and the real bottleneck turns out not to be compute.
Meet AgentWorks: Your Business’s Most Valuable Employee Never Calls in Sick
Enterprise-grade AI agents designed specifically for businesses that value data privacy and operational efficiency. Unlike ChatGPT, AgentWorks agents are trained on your business and keep your data completely private.
The AWS Outage That Broke AI: What March’s Infrastructure Crisis Reveals About Cloud Dependencies
On March 1st, 2026, a catastrophic failure at Amazon Web Services' data centers in the United Arab Emirates sent shockwaves through the global AI ecosystem. What began as fires and emergency power shutdowns at AWS facilities quickly cascaded into a worldwide infrastructure crisis that exposed a uncomfortable truth: our AI future is [Read more...]