Same AI Model, Two Hardware Tiers — And Why Context Length Is the Hidden Variable
Modular Technology Group · April 20, 2026
Ask any AI vendor how fast their stack runs and you’ll get a single headline number. “40 tokens per second.” “Under a second to first token.” Impressive — until you realize the benchmark prompt was 200 words long and you’re planning to feed it a 300-page document.
This week we took Qwen 3.6 35B-A3B — a state-of-the-art Mixture-of-Experts model released a few days ago — and pointed it at two very different pieces of hardware. Same model. Same questions. Same quantization tier (4-bit). Only the hardware changed.
The result isn’t just a horse race. It’s a quiet lesson in why the specs that matter for AI aren’t always the specs that get advertised.
Why We Ran This
At Modular, we route the same model across different infrastructure depending on the workload. A developer laptop handles quick, short-context tasks. A dedicated AI server handles long-document analysis, multi-turn agent reasoning, and anything that needs a big context window.
The question isn’t “which is faster.” A server beats a laptop. That’s boring.
The real question: at what context length does routing to the dedicated server become worth it? Without numbers, every routing decision is a guess. So we measured.
The Setup
| Platform | Hardware | Engine | Quantization |
|---|---|---|---|
| “Forge” — developer laptop | MacBook Pro M4 Max, 64 GB unified memory | LM Studio (MLX backend) | MLX 4-bit |
| “Reach” — dedicated AI server | 2× NVIDIA RTX 4070 Ti, 24 GB VRAM total | Ollama v0.11.10 (llama.cpp/GGUF) | Q4_K_M GGUF |
We ran the model at three context sizes — 32k, 64k, and 128k tokens — and measured how long each host took to generate a 256-token response. Three trials per cell. Temperature fixed at 0.1 for near-determinism. Prompt content matched byte-for-byte. Tokenizer output cross-checked. Apples to apples.
For the 128k results, we added six total trials across two independent sessions to nail the number down.
Result #1: One Host Stays Usable. The Other Doesn’t.
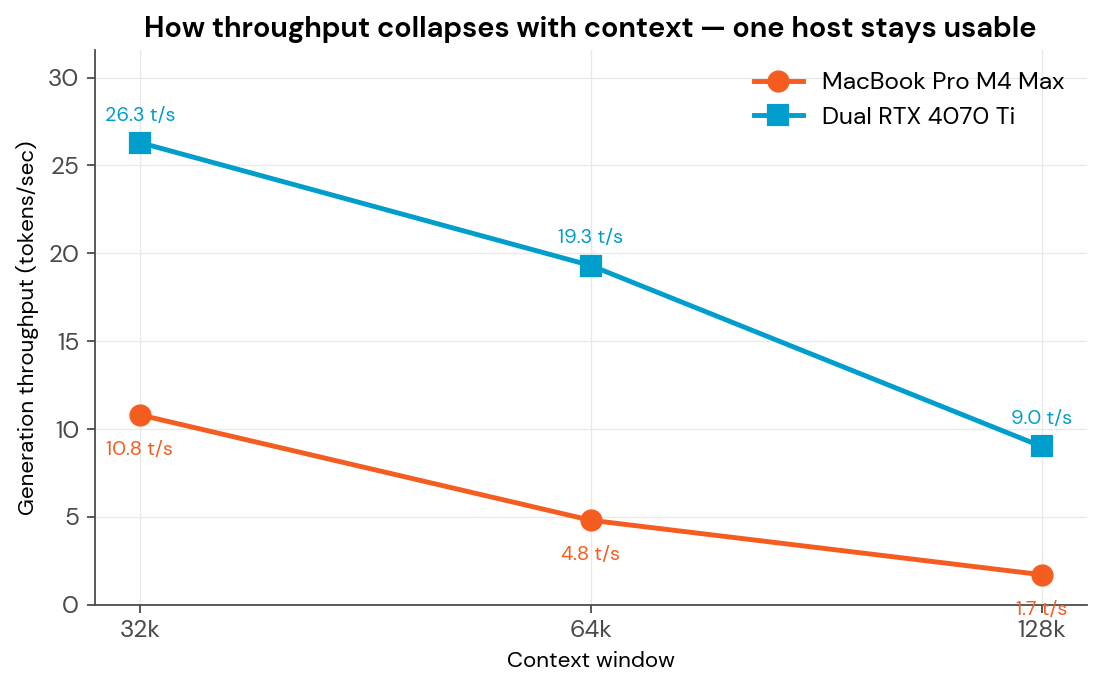
At 32k context, both platforms deliver workable performance. The MacBook runs at 10.8 tokens/sec — slower than the dedicated server, but perfectly fine for interactive chat.
Then the context grows.
At 64k, the MacBook drops to 4.8 tokens/sec. At 128k, it collapses to 1.7 tokens/sec.
The dedicated server, meanwhile, holds its shape:
| Context | Forge (MBP) | Reach (Dual GPU) | Reach advantage |
|---|---|---|---|
| 32k | 10.8 tok/s | 26.3 tok/s | 2.4× faster |
| 64k | 4.8 tok/s | 19.3 tok/s | 4.0× faster |
| 128k | 1.7 tok/s | 9.0 tok/s | 5.3× faster |
Notice the pattern: the gap widens with every doubling of context. This isn’t a flat advantage — it compounds. By the time you’re at 128k, the kind of window you need for whole-document analysis or agent reasoning, the server is over five times faster than the laptop.
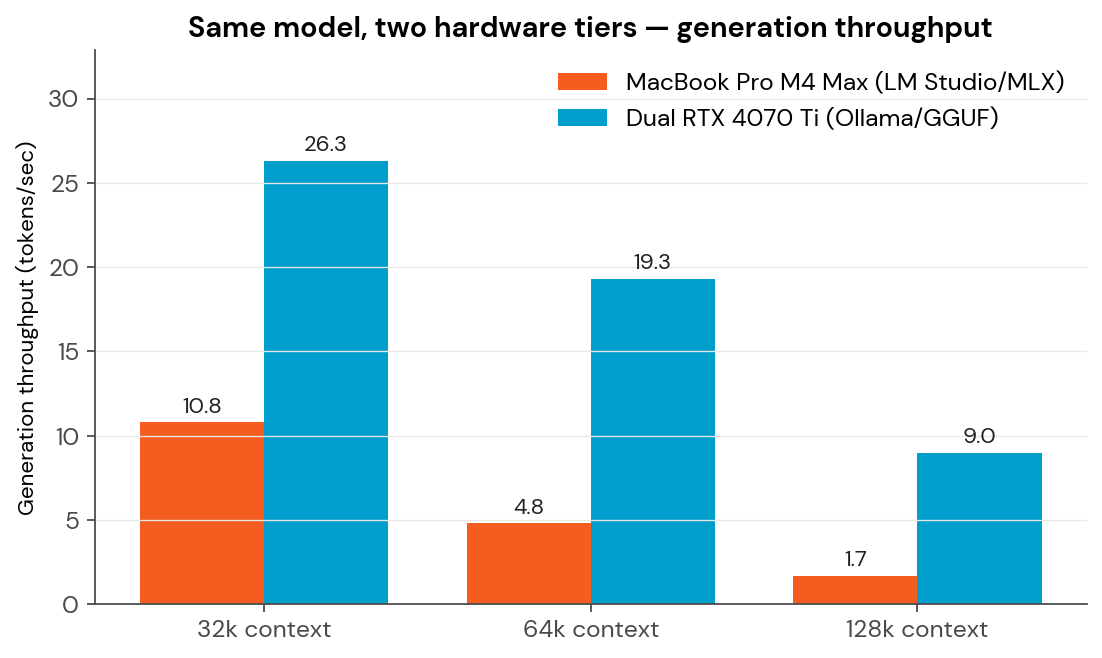
Result #2: The Honest Metric Is Wall Time
Tokens-per-second is abstract. What does this actually feel like to a human waiting for an answer?
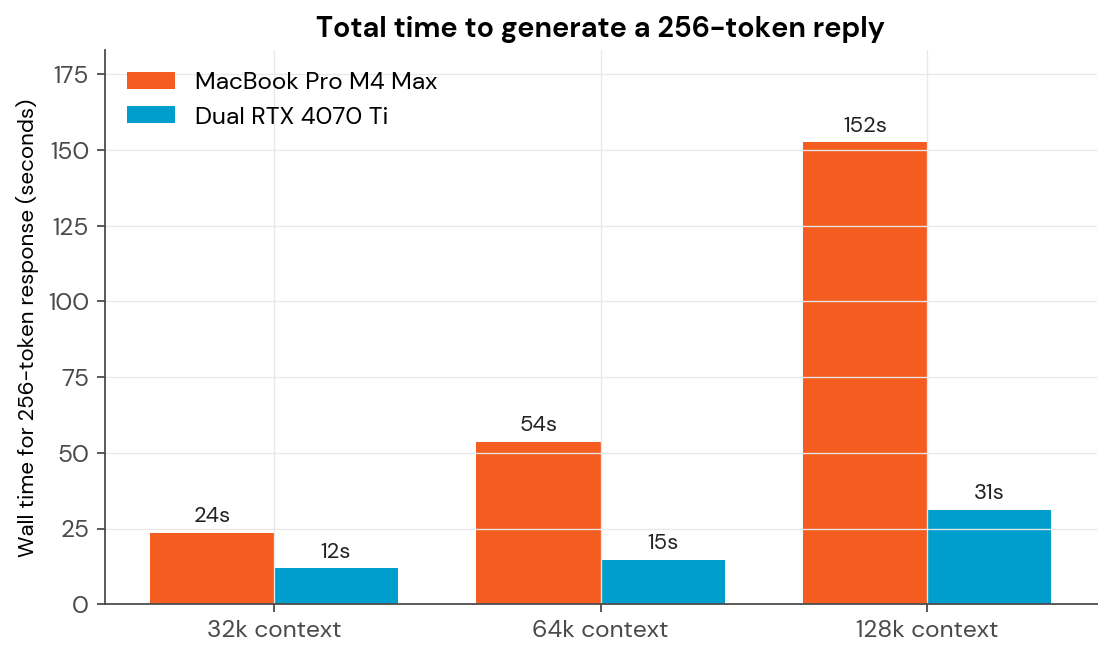
A 256-token reply — roughly one solid paragraph — takes:
| Context | Forge | Reach |
|---|---|---|
| 32k | 23 seconds | 12 seconds |
| 64k | 54 seconds | 15 seconds |
| 128k | 2 minutes, 32 seconds | 31 seconds |
That’s the difference between a tool you can hold a conversation with and a tool you fire off and check back on later.
Result #3: The Bottleneck Isn’t What You Think
Here’s where it gets interesting.
During the 128k runs on the dedicated server, we monitored both GPUs continuously. The VRAM was pegged — 22.2 GB of 24 GB total, 91% saturation. So the GPUs must have been pegged too, right?
Not even close.
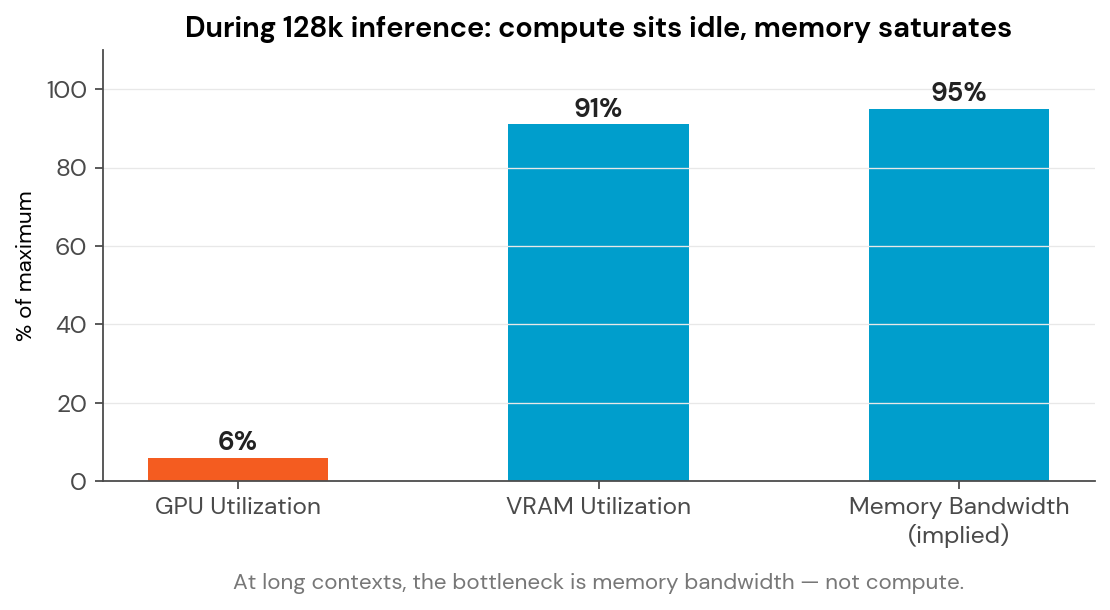
The two GPUs, theoretically capable of hundreds of trillions of operations per second, sat at 6–7% utilization. They weren’t waiting for work. They were waiting for memory.
At long context lengths, the model has to read the entire “KV cache” — every token it’s seen so far — to generate each new token. Enormous quantities of data move between VRAM and the compute cores every few milliseconds. The memory bus becomes the choke point long before the math does.
This is the single most important finding in the entire exercise, because it reframes how to evaluate future hardware.
More FLOPS won’t fix this. When the question becomes “should we buy the next card when it drops?” — the answer starts with its memory bandwidth spec, not its TFLOPS number. That’s the opposite of what most marketing collateral emphasizes.
The Same Story, Live From Production Telemetry
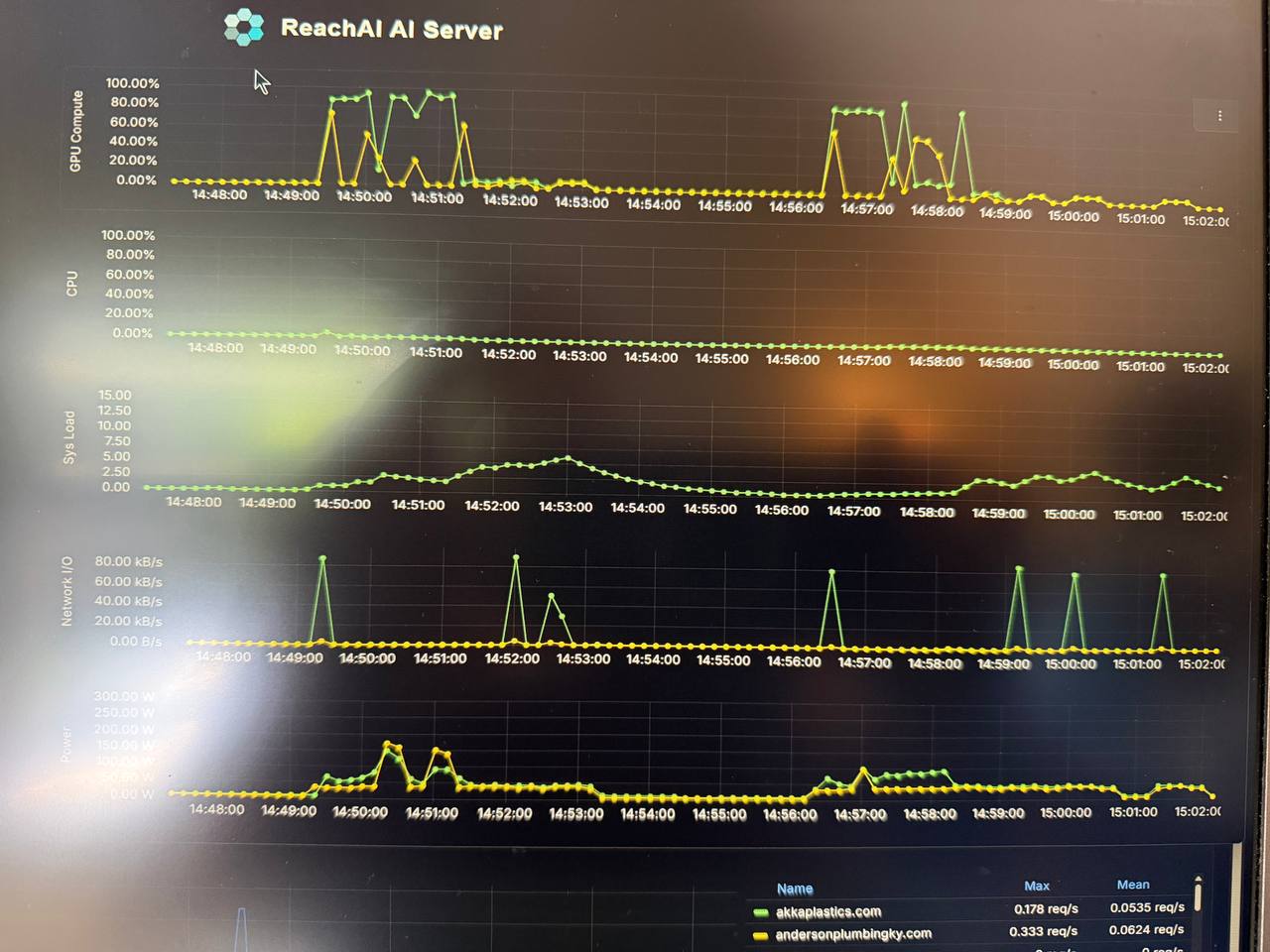
This is real production monitoring from our own dashboard during the benchmark — not synthetic charts. Three things worth noticing:
- Both GPU panels are nearly identical. Both cards track the same 5–7% load pattern. That’s tensor parallelism working.
- The staircase in “Total Memory Used.” Each step is a single 128k trial committing its KV cache, then holding it. Three trials, three plateaus, climbing toward the 24 GB ceiling.
- Compute is flat. Memory is climbing. The shape of the real data tells the same story as the synthetic chart: this workload lives and dies by memory, not by compute.
This is the visibility that separates production AI infrastructure from “we installed it and hope it works.”
Result #4: Tensor Parallelism Done Right
One thing the dedicated server does exceptionally well: split the model cleanly across both GPUs.
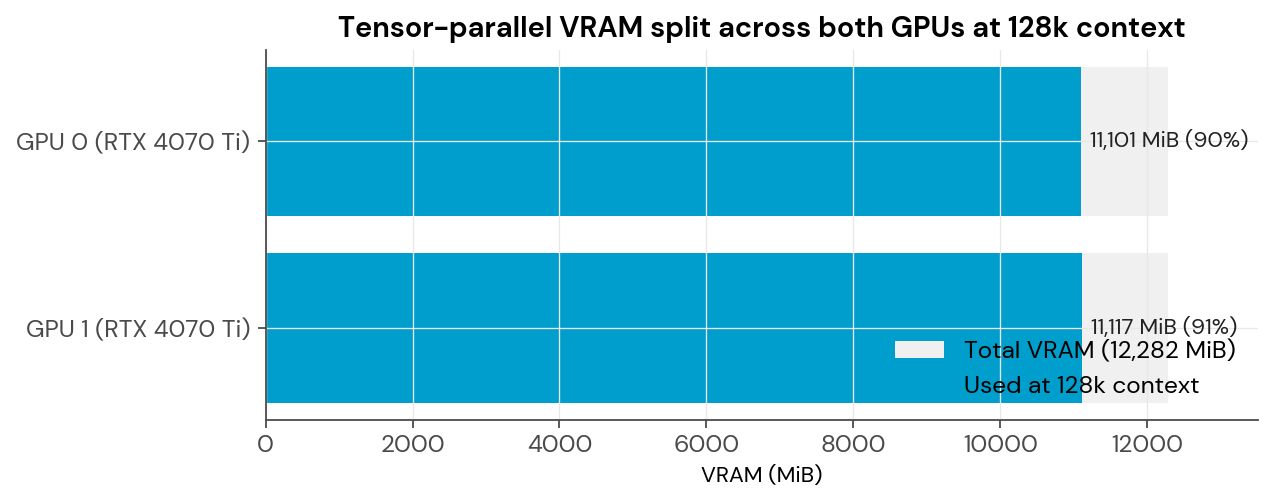
At 128k context, the memory load is nearly identical on both cards — 11,101 MiB on GPU 0, 11,117 MiB on GPU 1. A difference of 16 MiB out of over 11,000. That’s Ollama’s tensor-parallel splitter working exactly as designed. No card is bearing extra load. No GPU is OOMing. No spillover to CPU.
Tensor parallelism isn’t automatic. It requires compatible hardware, deliberate configuration, and a runtime that actually supports it. It’s also invisible to the end user — which is exactly how it should be.
What This Means for How You Deploy AI
If you’re prototyping against 4k-to-16k prompts on a decent laptop, you’re fine. For a team running real AI applications against real-world documents, the math shifts quickly.
A few honest observations from this data:
- Context length matters more than model size. A 35B-parameter model can feel snappy or geological depending entirely on how much context you feed it. Marketing benchmarks rarely mention this.
- Hardware choice is a memory problem, not just a compute problem. Two mid-range GPUs with balanced VRAM can outperform much more expensive single-GPU setups for long-context work.
- Consumer hardware has real limits. M-series Macs are remarkable for the price. But physics is physics. There’s a reason production AI workloads live on dedicated servers.
- Private infrastructure isn’t only about sovereignty. It’s also about having the right hardware for the right context, predictable performance, and the ability to scale without a surprise cloud bill.
At Modular, we deploy private AI infrastructure that gets these details right — matching the model, the quantization, the hardware, and the runtime so answers come back in seconds, not minutes. Data stays private. Costs stay fixed. Performance stays predictable.
Your data, your rules. Your hardware, matched to your workload.
Appendix: Methodology & Caveats
Model: Qwen 3.6 35B-A3B (Mixture-of-Experts — 36B total parameters, 3B active per token)
Prompts: Synthetic filler text sized to 85% of target context, with a single consistent question appended. Byte-identical across both hosts. Tokenizer output verified to match (prompt_tokens reported identically on each side).
Trials: Three per context-size × host cell for the primary run. Six additional trials at 128k on the dedicated server across two independent sessions. Variance across all six 128k runs: under 2% (8.94–9.03 tok/s).
Completion target: 256 tokens, temperature=0.1.
Ollama configuration: Explicit num_ctx override on every request. Default caps context at 4,096 tokens — enough to silently invalidate every long-context test if you miss it.
Caveats:
- Quantization formats differ (MLX 4-bit vs Q4_K_M GGUF). Both are 4-bit but not bit-identical.
- The MacBook was running normal background workloads during the test, not dedicated. A clean bench would improve its numbers modestly but not flip the conclusion.
- Single model tested. Different architectures — dense transformers, larger MoEs, specialized coding models — will scale differently.
- The 6–7% GPU utilization figure reflects generation phase only. Prompt evaluation phase utilization was much higher, but brief.
Raw data and all benchmark scripts: Available on request. Fully reproducible.
Modular Technology Group builds and hosts private AI workspaces with open-source components, in a FedRAMP data center. We use what we sell.