The Model That Barely Slows Down: Gemma 4 26B vs Qwen 3.6 35B at Long Context
Modular Technology Group · April 22, 2026
I’ve been thinking a lot about what it means to deploy a model in production versus benchmark it in a controlled setting. Most benchmarks pick short prompts — 1k, 2k tokens — and declare a winner. That’s fine for answering quick questions. It’s irrelevant if you’re building anything real: document analysis, long-thread summarization, multi-turn reasoning agents, whole-repo code review.
So we don’t benchmark that way.
Two days ago we published numbers for Qwen 3.6 35B-A3B across 32k, 64k, and 128k contexts on our dedicated AI server. Today we ran the same protocol against Google’s brand-new Gemma 4 26B — same hardware, same quantization, same prompts, same three-context sweep.
The headline: Gemma 4 26B is 3.7× faster than Qwen 3.6 35B-A3B at 32k context. At 128k, it’s 7.2× faster.
And unlike Qwen 3.6 — which we watched degrade from 26 tokens/sec at 32k to 9 tokens/sec at 128k — Gemma 4 barely moves. It went from 96 to 87 to 65 tokens/sec. The curve is nearly flat. That changes the infrastructure calculus entirely.
The Setup
Same hardware as Monday’s Qwen bench. Same server. Same protocol.
| Platform | Hardware | Engine | Quantization |
|---|---|---|---|
| “Reach” — dedicated AI server | 2× NVIDIA RTX 4070 Ti, 24 GB VRAM total | Ollama (llama.cpp/GGUF) | Q4_K_M |
Models under test:
- Gemma 4 26B (Google, MoE A4B — ~4B active parameters per token, 26B total)
- Qwen 3.6 35B-A3B (Alibaba, MoE A3B — ~3B active parameters per token, 36B total)
Protocol matches our April 20 baseline bench:
- Context windows: 32k, 64k, 128k tokens
- Prompt: synthetic filler at 85% of target context budget — same bytes both models
- Completion: 256 tokens, temperature 0.1
- Trials: 3 measured per cell (+ 1 warm-up discarded per model×context)
- Model unloaded between runs — no contamination from the other model’s KV cache
- Explicit
num_ctxoverride on every Ollama request (Ollama silently caps at 4,096 without it — we learned this the hard way and documented it)
18 total runs. 0 failures. Variance: under 1% across all trials.
The Numbers
| Context | Gemma 4 26B | Qwen 3.6 35B-A3B | Gemma advantage |
|---|---|---|---|
| 32k | 96.4 tok/s · 3.5s wall | 26.3 tok/s · 11.5s wall | 3.7× |
| 64k | 86.7 tok/s · 4.1s wall | 19.3 tok/s · 15.7s wall | 4.5× |
| 128k | 65.2 tok/s · 5.9s wall | 9.1 tok/s · 31.4s wall | 7.2× |
Let me frame the wall-clock numbers concretely. A 256-token response — roughly one dense paragraph — takes:
- Gemma 4 at any context: under 6 seconds
- Qwen 3.6 at 32k: 11.5 seconds
- Qwen 3.6 at 64k: 15.7 seconds
- Qwen 3.6 at 128k: 31.4 seconds
That’s the difference between a tool you hold a conversation with and one you fire off while you pour another cup of coffee.
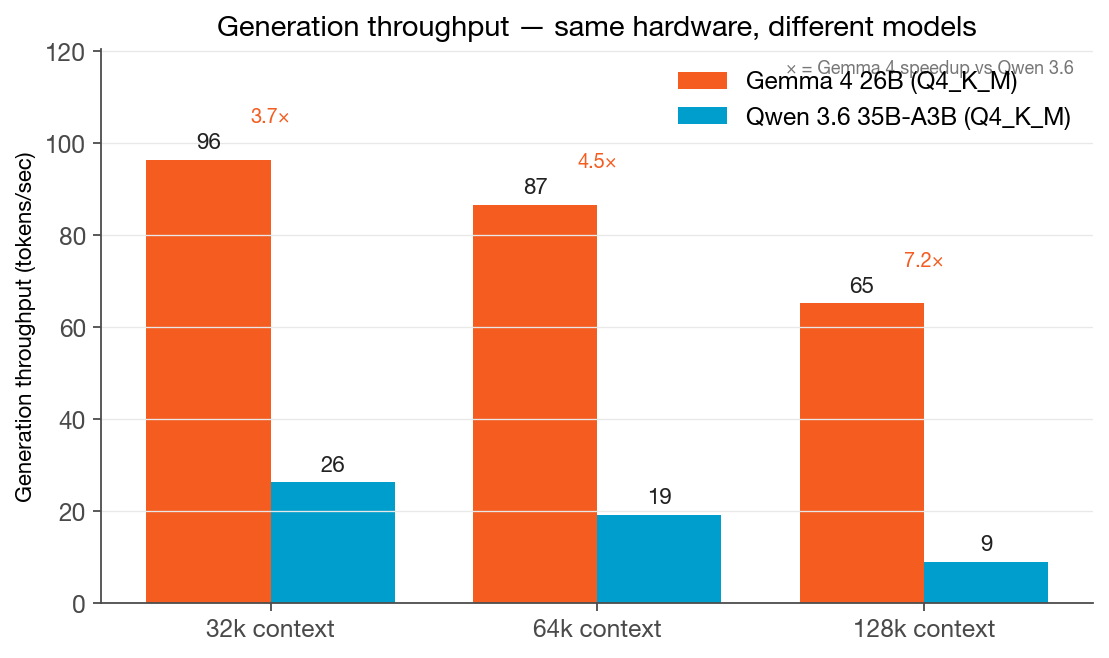
The Surprise Finding: The Architecture Gap Widens With Context
Here’s where I want to spend more time, because this isn’t just a “new model is faster” story.
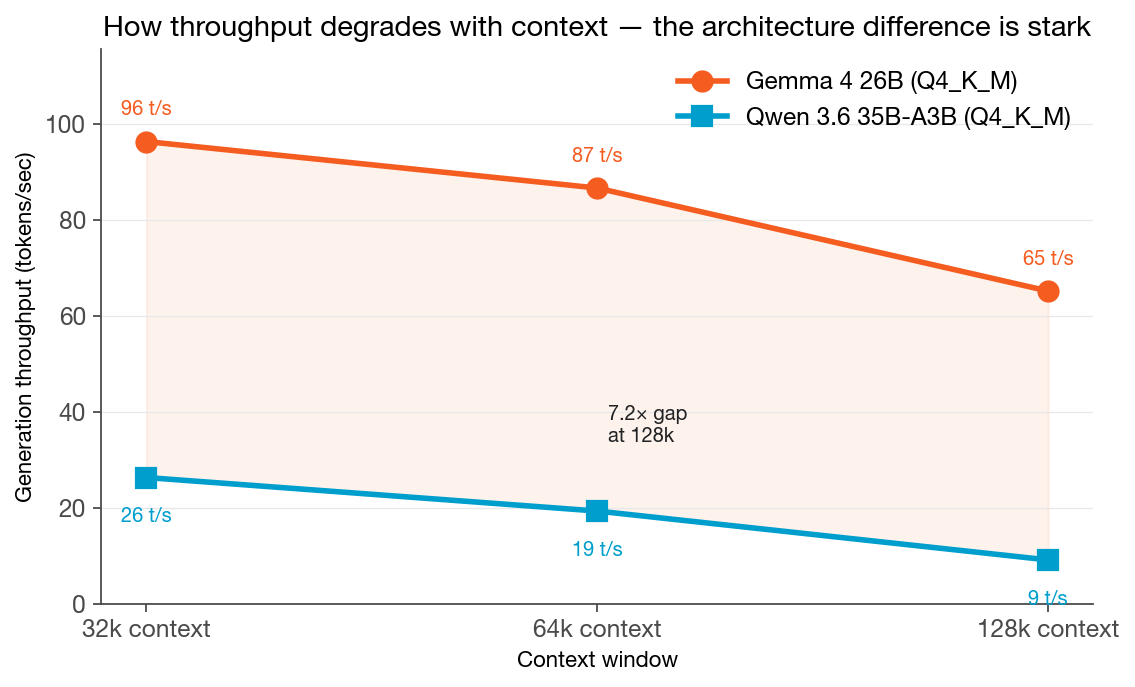
Both models are Mixture-of-Experts. Both use Q4_K_M quantization. Both run on the same two GPUs. At 32k context, the gap is already 3.7×. By 128k, it’s 7.2×. The gap nearly doubles as the context grows.
Why?
Qwen 3.6 35B-A3B:
- 36B total parameters, ~3B active per token
- At 128k context, generation drops to 9.1 tok/s
- Degradation from 32k to 128k: -65%
Gemma 4 26B:
- 26B total parameters, ~4B active per token
- At 128k context, generation holds at 65.2 tok/s
- Degradation from 32k to 128k: -32%
The KV cache grows linearly with context. At 128k, both models are operating under the same VRAM pressure we documented Monday — memory bandwidth is the bottleneck, not compute. The GPUs are reading enormous amounts of data per generated token.
The difference is the underlying architecture. Gemma 4’s A4B configuration activates more parameters per token than Qwen 3.6’s A3B, which would normally suggest higher compute overhead. But the total parameter count is smaller (26B vs 36B), meaning the weight tensors being loaded from VRAM on each generation step are physically smaller. Less data to move per token. Less memory bandwidth consumed per token. The gap widens with context precisely because the bandwidth-bound regime amplifies parameter-count differences.
In short: at long context, smaller total parameter count beats higher active parameter count when you’re memory-bandwidth constrained.
This is the kind of finding that doesn’t show up in a 2k-token benchmark.
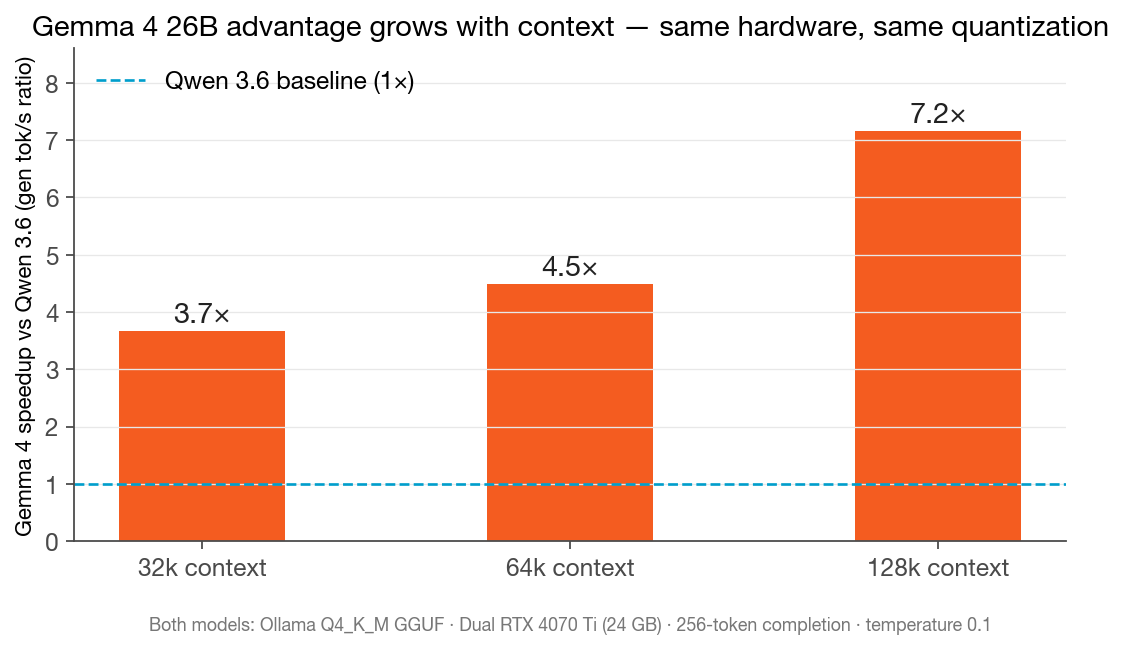
What This Means for Infrastructure Selection
The previous bench taught us that hardware tier matters: dual mid-range GPUs on a dedicated server outperformed an M4 Max laptop by 5.3× at 128k. This bench teaches something different — that model architecture matters just as much as hardware for long-context workloads.
A few things I’m taking away from this:
Context length changes the whole model-selection calculus. Qwen 3.6 35B-A3B is an excellent model. For reasoning tasks at moderate contexts, it’s still compelling. But if your workload involves 64k+ prompts — and an increasing number of real workloads do — the throughput differential is severe enough to matter operationally. A 7.2× speed penalty at 128k context isn’t a marginal difference; it’s a different class of tool.
Model architecture is an infrastructure decision, not just a capability decision. When selecting a model for a production deployment, we now explicitly consider the active-parameter count, total parameter count, and their ratio alongside benchmark capability scores. Two MoE models with similar benchmark performance can behave completely differently under sustained long-context load.
The bandwidth-bottleneck pattern generalizes. We saw last week that at 128k context, the GPUs were running at 6–7% compute utilization with VRAM saturated at 91%. The compute was idle. The memory bus was the choke. Gemma 4 takes advantage of this constraint by keeping its weight tensor smaller — it’s effectively doing less memory I/O per token, which is exactly what you want when the memory bus is your ceiling.
Smaller isn’t always slower. The conventional wisdom is that a 36B model is “better” than a 26B model — more parameters, more capacity. For generation throughput under memory-bandwidth constraints, the relationship inverts. Whether Gemma 4 produces better *output quality* than Qwen 3.6 for a given task is a separate question — one worth benchmarking rigorously — but on pure throughput at long context, the smaller model wins decisively.
An Honest Note on Prompt Eval Telemetry
In our Qwen benchmark, Ollama reported prompt ingestion speeds of 20k–44k tokens/sec across the three context sizes — a useful data point for pipeline latency estimation.
For Gemma 4, Ollama’s prompt_eval_duration consistently reported 13–19ms across all three context windows, implying millions of tokens/sec. This is a KV-cache reuse artifact: the warm-up trial primes the cache, and subsequent trials appear to skip most or all of the ingestion phase. We’re reporting this honestly rather than publishing the inflated numbers. The wall-clock timing captures the full end-to-end latency accurately; the prompt_eval field in Ollama’s response for Gemma 4 requires more investigation before we’d cite it confidently.
What we can say: if Gemma 4 is achieving genuine KV-cache reuse across sequential requests with the same prompt prefix, that’s actually a meaningful throughput advantage for multi-turn workloads. We’ll dig into this in a follow-up run with cold-cache isolation.
What’s Next
Two tests I want to run before I’m satisfied this benchmark is complete:
1. Cold-cache prompt eval isolation for Gemma 4 — force model reload between every trial to get a clean first-ingestion measurement 2. Output quality comparison — throughput advantage is only relevant if the output quality holds up. We’ll run a structured evaluation comparing Gemma 4 and Qwen 3.6 on legal document analysis and long-form synthesis tasks — the actual workloads our clients care about
The throughput finding is real and significant. Whether Gemma 4 earns its place in the production stack depends on the quality side of the equation.
The Infrastructure View
For organizations evaluating private AI: the model landscape is moving fast, and the performance characteristics of new models don’t always fit the pattern of what came before. A model selection decision from six months ago might be suboptimal today — not because the old model got worse, but because the new options are sufficiently different architecturally.
This is part of why we run these benchmarks with our own hardware and real workloads rather than relying on published leaderboard numbers. Leaderboards optimize for benchmark performance. We care about throughput under the memory constraints of actual production hardware, at the context lengths real workloads require.
Modular doesn’t resell AI. We build, host, and run the infrastructure ourselves — which means we’re measuring what actually matters to us operationally. These numbers are real because they have to be.
If you’re working through a private AI infrastructure decision and want to compare notes, I’m always open to the conversation.
Appendix: Methodology & Caveats
Models:
- Gemma 4 26B (Google DeepMind) — Ollama tag
gemma4:26b, GGUF Q4_K_M, 17.9 GB, digest5571076f3d70 - Qwen 3.6 35B-A3B (Alibaba) — Ollama tag
qwen3.6:35b-a3b, GGUF Q4_K_M, 23.9 GB, digest07d35212591f
Hardware: ReachAI server, 2× NVIDIA RTX 4070 Ti (12 GB VRAM each, 24 GB total), Ubuntu 24.04, Ollama v0.11.10
Prompt construction: Same filler text (140-char repeating unit), calibrated to 85% of target token budget. Tokenizer calibration ran 2026-04-22: Gemma 4 measures 6.76 chars/token, Qwen 3.6 measures 6.81 chars/token — within 1%. Same prompt bytes sent to both models; both reported nearly identical prompt_eval_count (26,639 vs 26,632 at 32k; 53,259 vs 53,252 at 64k; 106,479 vs 106,472 at 128k), confirming tokenizer parity.
Trial structure: 1 warm-up trial discarded per model×context cell (model remained loaded for context-cache consistency), then 3 measured trials. Model explicitly unloaded between models using Ollama’s keep_alive: 0 mechanism to prevent cross-contamination.
Completion: 256 tokens, temperature=0.1.
Ollama: Explicit num_ctx override per request. Default silently caps at 4,096 tokens.
Variance: Under 1% across all trials for both models. Gemma 4: 96.4 / 96.6 / 96.4 at 32k; 65.2 / 65.3 / 65.2 at 128k. Rock solid.
Caveats:
- Gemma 4 prompt eval timing is not reported due to KV-cache reuse masking cold-start latency in Ollama. Wall-clock timing is accurate.
- Both models use Q4_K_M GGUF — same quantization scheme, though the underlying weight distributions differ.
- Tests executed on a dedicated server with no competing workloads.
- Output quality comparison not included in this benchmark — throughput only.
Reproducibility: All scripts and raw data archived at reports/bench-archive/2026-04-22-gemma4-vs-qwen36/. Benchmark harness is argparse-driven and can be re-run against any Ollama endpoint.
Cale Hollingsworth is the founder of Modular Technology Group, which builds and hosts private AI workspaces in a FedRAMP data center. He has been advising organizations on infrastructure strategy since 1993. LinkedIn: Fractional CTO | Private AI Infrastructure Strategist | Evangelist @ Modular Technology Group | RAG Architect | Future-Proofing Organizations Since 1993
#PrivateAI #DataPrivacy #yourdatayourrules